
当ページではpandas.DataFrameのエクスポート方法を記載している。
当ページではユースケースとその場合のコードを記載した上で、各記載の意味を説明している。
1.実行例
pandas.DataFrameのデータをCSVとExcelファイルに書き込むコードは以下。
import pandas as pd
import numpy as np
import os
folder_path = os.path.dirname(__file__)
input_folder_path1 = os.path.join(folder_path,"test1.csv")
input_folder_path2 = os.path.join(folder_path,"test2.csv")
input_folder_path3 = os.path.join(folder_path,"test3.xlsx")
input_folder_path4 = os.path.join(folder_path,"test4.xlsx")
df = pd.DataFrame(np.array([[1, 2, 3], [6, 5, 4], [7, 7, 7]]),
columns=['a', 'b', 'c'],index=['d', 'e', 'f'])
print("初期データ")
print(df)
df.to_csv(input_folder_path1, index=False)
df.to_csv(input_folder_path2, index=True)
df.to_excel(input_folder_path3, index=False)
df.to_excel(input_folder_path4, index=True) 5~9行目は出力先のPathを指定している。
csv・excelともに出力時の拡張子は[csv]や[xlsx]のように全て小文字で指定する必要がある。
11~14行目はデータの作成を行っている。
15~19行目はCSVとExcelファイルへの出力を行っている。
indexはFalseを指定している場合は列名が表示されず、
Trueを指定している場合は列名が表示される。
プロンプトの実行結果:
初期データ
a b c
d 1 2 3
e 6 5 4
f 7 7 7ファイルの出力結果:
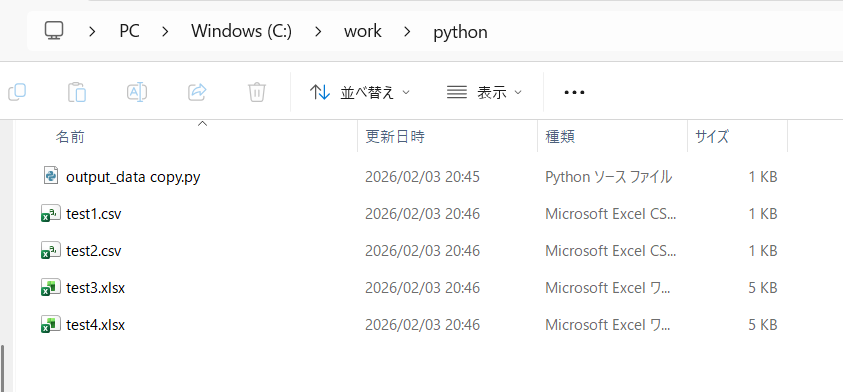
test1.csv:
index=Falseのため、列名が表示されずに出力される。
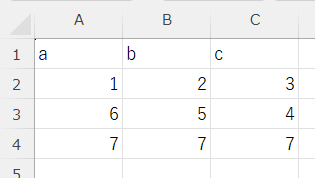
test2.csv:
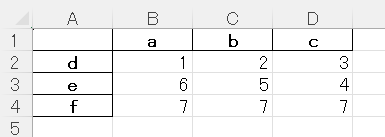
index=Trueのため、列名が表示されて出力される。
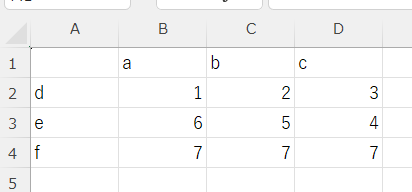
test3.xlsx:
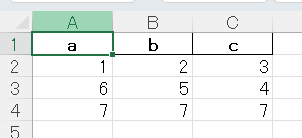
test4.xlsx
2.参考
公式ドキュメント:
to_csv
https://pandas.pydata.org/pandas-docs/version/2.3/reference/api/pandas.DataFrame.to_csv.html
to_excel
pandas.DataFrame.to_excel — pandas 2.3.3 documentation
表の作成
pandas.DataFrameの表を作成する方法 | エクヌツITブログ
pandas値の取得・更新・削除
pandas.DataFrameの値の取得・更新・削除 | エクヌツITブログ
pandasのデータの検索
pandas.DataFlameのデータ検索(loc,iloc,query) | エクヌツITブログ
pandasのカラム追加・削除
pandasのカラム追加・削除(assign・drop) | エクヌツITブログ
pandasのインポート
pandasのインポートread_csv,read_excel | エクヌツITブログ
pandasの要素数取得
pandas.DataFrame要素数を取得size,count | エクヌツITブログ

コメント